
Today OpenAI has taken another major step in the development and deployment of advanced AI models by releasing ChatGPT o1-preview and ChatGPT o1-mini. These models have undergone extensive safety evaluations and risk assessments, focusing on their advanced reasoning capabilities and potential frontier risks. OpenAI has implemented robust red-teaming efforts, external evaluations, and internal safeguards to ensure that these models are safe to deploy in real-world applications. Lets take a closer look at OpenAI’s external red teaming, frontier risk evaluations, and the safeguards put in place to manage the potential risks associated with the o1 model series.
Quick Links:
- Why Safety and Risk Evaluations Are Crucial
- External Red Teaming
- Frontier Risk Evaluations
- Preparedness Framework and Risk Assessments
- Key Safeguards and Mitigations
Key Takeaways:
- ChatGPT o1-preview and ChatGPT o1-mini models underwent rigorous external red-teaming and frontier risk evaluations before deployment.
- These evaluations assessed potential risks such as hallucinations, disallowed content generation, fairness, and dangerous capabilities.
- o1-preview and o1-mini achieved improved safety performance through advanced reasoning, making them more resilient to unsafe content generation.
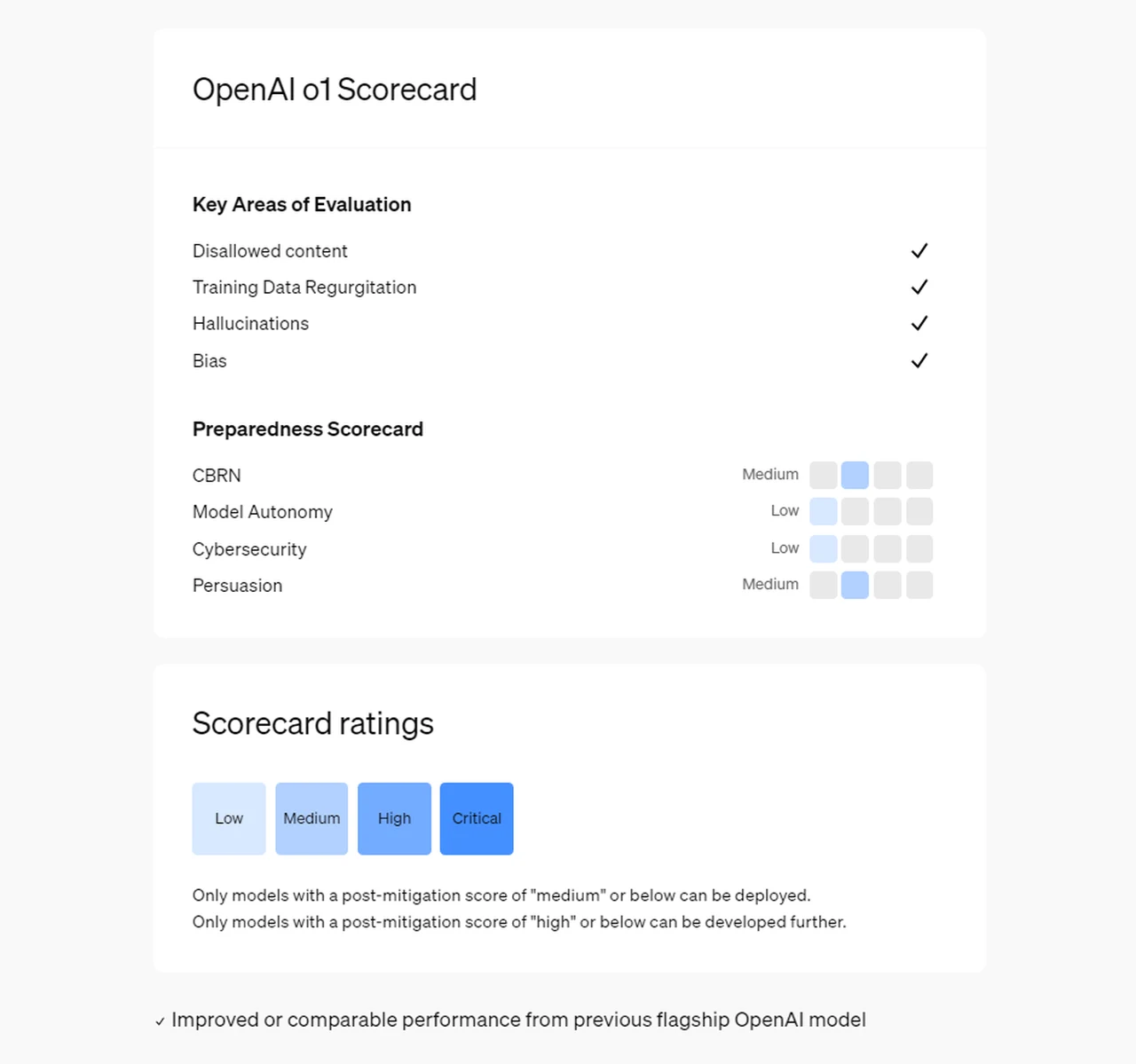
- OpenAI’s Preparedness Framework rated the o1 series as having a “medium” overall risk, with “low” risks in cybersecurity and model autonomy.
- Extensive safeguards like blocklists, safety classifiers, and alignment techniques were put in place to mitigate frontier risks.
As AI models become more advanced, the complexity of potential risks associated with their deployment increases. OpenAI’s o1-preview and o1-mini models are trained with large-scale reinforcement learning, enabling them to reason through problems in a way that resembles human thought processes. While this advanced reasoning capability enhances their performance, it also introduces new risks, particularly when dealing with potentially harmful or unsafe prompts.
OpenAI o1 System Card
Without rigorous safety evaluations, models could be vulnerable to misuse, such as generating disallowed content, engaging in harmful stereotypes, or succumbing to jailbreak attempts. Therefore, OpenAI’s commitment to external red teaming and frontier risk evaluations is essential to ensure that these models are not only effective but also safe for widespread use.
External Red Teaming
External red teaming is a process where independent experts test the AI models to identify weaknesses, vulnerabilities, and potential safety issues that may not be immediately apparent during internal testing. In the case of o1-preview and o1-mini, OpenAI worked with external red teams to stress-test the models’ capabilities across a wide range of scenarios, particularly those that could lead to harmful or unsafe behavior.
The external red teams evaluated several risk categories, including:
- Disallowed Content Generation: Assessing the models’ ability to handle prompts that could lead to the generation of harmful or disallowed content, such as violence, hate speech, or misinformation.
- Demographic Fairness: Evaluating whether the models were biased in their responses, particularly when dealing with sensitive topics related to race, gender, or other demographics.
- Jailbreak Resistance: Testing the models’ robustness against attempts to bypass safety protocols through adversarial prompts or manipulations.
- Hallucination Reduction: Identifying instances where the models may generate false or misleading information without clear grounding in factual data.
The results of these evaluations showed that o1-preview and o1-mini performed better than previous models, particularly in their ability to reason through safety rules and avoid generating unsafe or disallowed content. This improvement can be attributed to their advanced reasoning capabilities, which enable the models to think critically about the context of their responses before generating an output.
Frontier Risk Evaluations
Frontier risks refer to potential risks posed by cutting-edge technologies that push the boundaries of what AI is capable of. For the ChatGPT o1-preview and ChatGPT o1-mini models, these risks include capabilities that could be exploited in ways beyond existing AI systems, particularly as they relate to intelligence amplification, persuasion, and autonomous decision-making.
OpenAI conducted frontier risk evaluations to assess how the o1 series performs in relation to potential high-stakes scenarios, such as:
- Cybersecurity Risks: Ensuring that the models do not inadvertently aid in generating or recommending malicious code or harmful cybersecurity advice.
- CBRN (Chemical, Biological, Radiological, and Nuclear) Threats: Assessing whether the models could be misused to generate content related to hazardous or dangerous technologies.
- Persuasion and Manipulation: Evaluating whether the models could be leveraged to manipulate users or influence decision-making in ways that might lead to harm.
The evaluations found that while o1-preview and o1-mini’s advanced reasoning capabilities offer substantial benefits, they also introduce new challenges. The ability of the models to reason deeply through prompts can, in some cases, increase the risk of unintended outputs in certain high-risk areas. However, OpenAI’s implementation of extensive safety protocols has mitigated these risks to an acceptable level, with the models receiving a “medium” risk rating overall and a “low” risk rating for cybersecurity and model autonomy.
Preparedness Framework and Risk Assessments
The Preparedness Framework is OpenAI’s comprehensive approach to evaluating and mitigating risks associated with advanced AI models. This framework includes both internal and external evaluations, along with frontier risk assessments that gauge the safety and alignment of new models.
For the o1 series, OpenAI’s Safety Advisory Group, Safety & Security Committee, and the OpenAI Board reviewed the models’ risk profiles and the safety measures that were implemented. The Preparedness Framework rated the ChatGPT o1-preview and ChatGPT o1-mini models as “medium” risk overall, noting that these models do not introduce capabilities beyond what is possible with existing AI systems, though they present some increased risks in specific areas, such as CBRN and Persuasion.
Key Safeguards and Mitigations
OpenAI has put several key safeguards in place to mitigate the risks associated with the o1-preview and o1-mini models. These safeguards include:
- Safety Classifiers: Models are equipped with classifiers that can identify and block disallowed content before it is generated.
- Blocklists: OpenAI has implemented comprehensive blocklists that prevent the models from producing content related to specific dangerous topics or harmful activities.
- Reasoning-Based Safeguards: The models’ ability to reason before answering allows them to apply safety rules more effectively, reducing the risk of harmful outputs.
- Robustness to Jailbreaking: The models have demonstrated increased resistance to jailbreak attempts, with a 59% improvement over previous models when tested with the StrongREJECT dataset.
In addition to these technical safeguards, OpenAI also conducted thorough red-teaming exercises, external audits, and safety assessments before deploying the models in ChatGPT and the API. The results from these evaluations were published in the OpenAI o1 System Card, providing transparency into the safety work carried out.
The release of ChatGPT o1-preview and ChatGPT o1-mini represents a significant advancement in AI reasoning, but it also highlights the importance of continued safety and alignment efforts. By thoroughly evaluating potential risks, implementing robust safeguards, and using external red-teaming to stress-test the models, OpenAI has set a new standard for responsible AI deployment. For more information read the Official OpenAI System Card Report.
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.