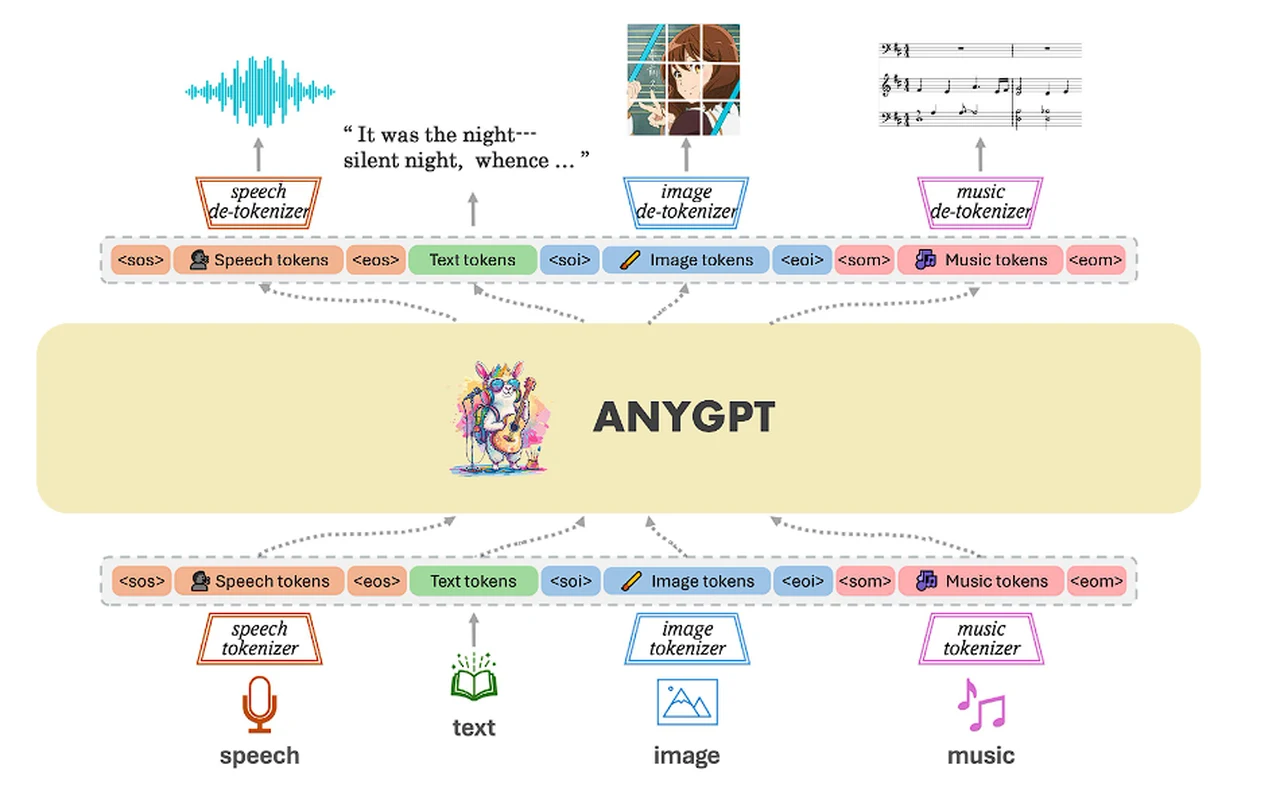
AnyGPT is an innovative multimodal large language model (LLM) is capable of understanding and generating content across various data types, including speech, text, images, and music. This model is designed to adapt to different modalities without significant modifications to its architecture or training methods.
The any-to-any open source multimodal LLM can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training.
It utilizes discrete sequence modeling to process and comprehend diverse information in a structured manner. This versatile tool is capturing the attention of developers and researchers alike, as it offers a glimpse into a future where AI can seamlessly engage with us across multiple senses. AnyGPT’s unique approach lies in its discrete sequence modeling technique, which breaks down complex information into smaller, more manageable pieces called tokens. This allows the model to process a wide range of data types with impressive accuracy. Whether it’s analyzing a detailed image or composing a piece of music, AnyGPT can handle the task with ease.
The development of AnyGPT has been a significant undertaking, involving the creation of a diverse dataset that includes various forms of speech, text, images, and music. This extensive training is what gives AnyGPT its remarkable ability to understand the nuances of different data types and how they can be combined or transformed. The result is an AI that can interact with humans in more natural and intuitive ways.
AnyGPT multimodal large language model

A key aspect of AnyGPT’s development is the creation of its dataset, which is not just about gathering multimodal content but also about enriching text-based interactions with rich, multimodal dialogues. This means that AnyGPT is not only an interpreter but also a creator, capable of generating outputs that can stimulate our senses in various ways.

Features of AnyGPT
One of the most exciting features of AnyGPT is its voice cloning technology. This allows the model to replicate any person’s speech, offering new opportunities for personalized communication. But AnyGPT’s talents don’t stop there; it can also write poetry, translate emotions into music, and create visual art, showcasing its potential as a powerful tool for creative expression.
- Unified Multimodal Capabilities:
- Can understand and work with various types of information, including speech, text, images, and music.
- Demonstrates the ability to handle different data modalities without requiring significant modifications to its architecture or training methodology.
- Discrete Sequence Modeling:
- Employs a method of breaking down information into smaller sequences or tokens, allowing it to process and understand diverse data types.
- Utilizes discrete tokenization for speech, text, images, and music, facilitating its multimodal integration.
- Automatic Content Generation:
- Capable of generating content that spans multiple data types, including visual art, music, and textual output, through an automatic, step-by-step approach.
- Examples include drawing images, creating music, writing poems, and crafting dramatic character lines, showcasing its versatility.
- Demonstrations of Practical Applications:
- Provides examples such as converting the feeling of music into images, translating emotions from pictures into music, and generating voice-based content.
- Demonstrates the ability to clone speech for content creation, like writing a poem in the cloned voice.
- Efficient Data Handling:
- The architecture is designed to be simple and efficient, maintaining effectiveness in processing inputs and generating outputs without needing extensive pre- or post-data preparation.
- Rich Training Dataset:
- Utilizes a comprehensive dataset containing mixed information (speech, text, images, music) to train the model on handling multimodal inputs.
- The dataset includes a wide variety of examples to ensure Any-GPT can manage and understand the nuances of different data types.
- Two-Stage Dataset Creation Process:
- Involves generating multimodal dialogues from textual conversations and incorporating diverse modalities such as images and audio to enrich the training dataset.
- Focuses on creating rich multimodal content, enhancing the model’s ability to understand and generate complex, multimodal responses.
For those who want to dive deeper into the workings of this AI, AnyGPT’s code is available as open-source. This means that anyone with an interest in AI can access the model, tweak it, and potentially improve its functionality. It’s an invitation to the community to participate in the ongoing development of this cutting-edge technology.
- Open-Source Availability:
- The code and resources related to Any-GPT have been made available, allowing researchers and developers to explore, experiment, and build upon the model.
- Community Engagement and Resources:
- Offers access to tools, consulting, networking, and collaboration opportunities through a Patreon community.
- Provides daily AI news, resources, and giveaways, fostering an engaged and informed community around the model’s developments and applications.
AnyGPT is more than just an AI model; it’s a sophisticated platform that expands the possibilities of multimodal AI interaction. Its ability to adapt to various data types, along with its open-source nature and supportive community, makes it an invaluable asset for anyone interested in the future of AI. AnyGPT represents a significant step forward in the field, providing a versatile platform for those eager to push the boundaries of what technology can do.
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Geeky Gadgets may earn an affiliate commission. Learn about our Disclosure Policy.